
Cyber Security
Researchers develop CAPTCHA solver to aid dark web research

A team of researchers at the Universities of Arizona, Georgia, and South Florida, have developed a machine-learning-based CAPTCHA solver that they claim can overcome 94.4% of real challenges on dark websites.
The study’s goal was to create a system that can streamline cyber threat intelligence, which currently requires human involvement for solving CAPTCHAs manually.
Cybercrime costs are rising exponentially, with cyberattacks and data breaches happening every day. As such, having a way to make the dark web more transparent for research is key to taking targeted preventive action.
Dark web CAPTCHAs
CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) is used by websites to differentiate between real users and bots.
These challenges are omnipresent on the dark web to protect platforms from the constant DDoS attacks that competing platforms launch against each other.
These DDoS attacks are carried out by botnets, and thus having a strong layer of CAPTCHA at the login page can keep the threat under control.
However, each website implements its own custom CAPTCHA challenge, making it practically impossible to develop a tool that can solve most of them.
As such, the collection of cyber-threat intelligence from illicit dark web markets and forums becomes challenging and expensive, as employees have to be involved in the CAPTCHA solving step.
Machine-learning approach
To address this practical problem, the researchers have developed a system that relies on interpreting rasterized images, which is qualitatively different from other recent studies that also used generative adversarial network-based approaches.

Source: Arxiv.org
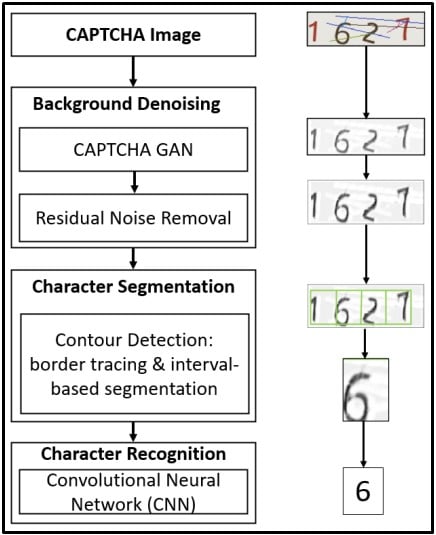
The new solver can distinguish letters and numbers by looking at them one by one, denoising the image, identifying their borders between letters, and segmenting the content into individual characters.
Source: Arxiv.org
As such, the size of the CAPTCHA challenge doesn’t affect the effectiveness of the solver much, especially when measuring accumulative performance for three attempts.

Source: Arxiv.org
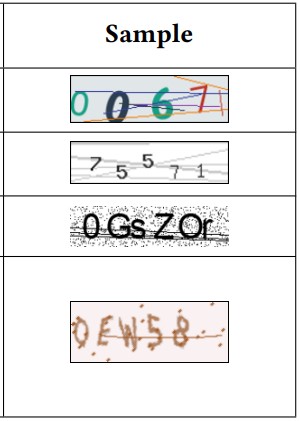
On the aspect of character recognition, the solver uses samples extracted across multiple local regions to identify fine-grained features such as lines and edges, so it can’t be “fooled” by character rotation, font size changes, or color mixups.
Source: Arxiv.org
Real-world testing
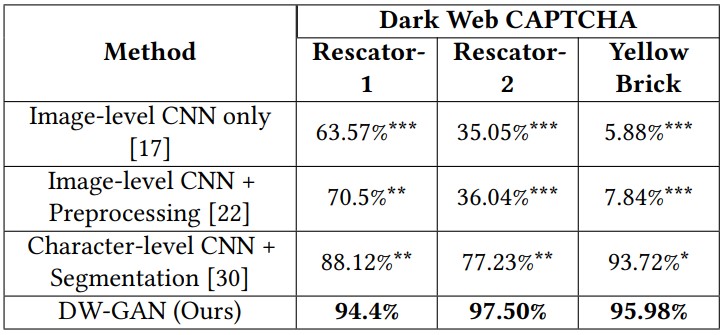
Using their most optimized DW-GAN solving model, the researchers tested it against Yellow Brick, a now-defunct dark web market that hosted illicit content listings.
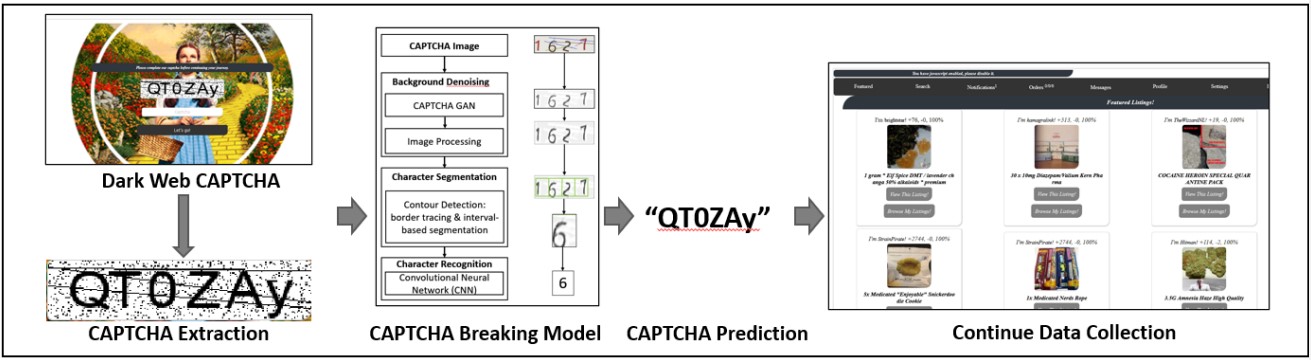
Source: Arxiv.org
As the paper explains:
Using a crawler enhanced by our DW-GAN, we were able to collect 1,831 illegal products from Yellow Brick. Among these products, there were 286 cybersecurity-related items, including 102 stolen credit cards, 131 stolen accounts, 9 forged document scans, 44 hacking tools, and 1,223 drug-related products.
Overall, collecting “Yellow Brick” market intelligence with DW-GAN took about 5 hours without human involvement. In particular, each HTTP request took 8.8 seconds for loading a new webpage; therefore crawling 1,831 pages took 268.5 minutes. Solving the recurring CAPTCHA challenges (per 15 HTTP requests) took our DW-GAN crawler 18.6 seconds.
Overall, the proposed framework could automatically break CAPTCHA with no more than three attempts. Breaking all CAPTCHA images take about 76 minuets [sic] in total for all 1,831 product pages, a process that is fully automated.
Of course, this testing data concerns a particular dark web market, but a similar performance level is expected on any site that employs word CAPTCHAs, according to the researchers.
Potential implications
Intelligence and highly-capable CAPTCHA solvers like this one can potentially disrupt the space, at least on the dark web where less sophisticated challenges are used.
Source: Arxiv.org
The authors have published the final version of their solver on GitHub, but not the training data set of 50,000 CAPTCHA images.
Someone could presumably work on this model to derive something that works on weak clearnet CAPTCHA implementations too.
As the paper emphasizes regarding this possibility: “while this study is mainly focused on dark-web CAPTCHA as a more challenging problem, the proposed method in this study is expected to be applicable to other types of CAPTCHA without loss of generality.”
This novel solver may have been developed for the noble purpose of tackling cybercrime, but it still holds the potential to impact those who use the dark web for anonymity and safe exchange of information.







IoT security threats highlight the need for zero trust principles

New infosec products of the week: October 27, 2023

Raven: Open-source CI/CD pipeline security scanner

Apple news: iLeakage attack, MAC address leakage bug

Hackers earn over $1 million for 58 zero-days at Pwn2Own Toronto
